Les tutoriels et articles¶
Vocabulaire et définitions¶
- Contenu (content): désigne, de manière générale, tout ce qui peut être produit et édité sur Zeste de Savoir, c’est-à-dire, à l’heure actuelle, un article ou un tutoriel. Tout contenu est rattaché à un dossier qui lui est propre et dont l’organisation est explicitée plus bas. Ce dossier comporte des informations sur le contenu lui-même (metadata : un auteur, une description, une licence...) ainsi que des textes, agencés dans une arborescence bien précise.
- Article : contenu, généralement court, visant à faire découvrir un sujet plus qu’à l’expliquer au lecteur (introduit sans rentrer dans les détails) ou à fournir un état des lieux sur un point donné de manière concise (rapports de release, actualité...).
- Tutoriel : contenu, en général plus long, ayant pour objectif d’enseigner un savoir-faire au lecteur.
- Tribune libre : ensemble de billets associés à un utilisateur.
- Billet : contenu, généralement court dont l’objectif est de donner un retour d’expérience, de donner son opinion quant à une actualité, de donner un lien intéressant… La validation (ou modération) d’un billet se fait après publication, publication étant directement faite par l’auteur.
- git: système de gestion de versions employé (entre autres) par ZdS. Il permet de faire coexister différentes versions d’un contenu de manière simple et transparente pour l’auteur.
- Version : état du contenu à un moment donné. Toute mise à jour du contenu (ou d’une de ses composantes) génère une nouvelle version de ce dernier, laquelle est désignée par un hash, c’est-à-dire par une chaîne de 40 caractères de long (aussi appelée sha, en référence à l’algorithme employé pour les générer). Ce hash permet d’identifier de manière unique cette version parmi toutes celles du contenu. Certaines versions, en plus du sha, sont désignées par un nom. On distingue ainsi la version brouillon (draft), la version en bêta (beta), la version en validation (validation) et la version publiée (public). Pour ce faire, les hash correspondant à ces versions sont simplement mis de côté.
- Fichier manifest.json : fichier à la racine de tout contenu dont l’objectif est de décrire ce dernier. Un tel fichier comporte deux types d’informations : à propos du contenu en lui-même (les métadonnées mentionnées plus haut) et à propos de son arborescence. La spécification de ce fichier est détaillée plus loin. On retiendra qu’à chaque version correspond un fichier
manifest.jsonet que le contenu de ce dernier peut fortement varier d’une version à l’autre. - Conteneur (container) : sous-structure d’un contenu. Explicité plus bas.
- Extrait (extract) : base atomique (plus petite unité) d’un contenu. Explicité plus bas.
De la structure générale d’un contenu¶
Des extraits¶
Un extrait est une unité de texte. Il possède un titre (title) et du texte (text). Dans l’interface d’édition d’un tutoriel, un extrait est désigné par le terme « section ».
Des conteneurs¶
Un conteneur est une boîte ayant pour rôle de regrouper des éléments sémantiquement proches. Il est caractérisé par son titre (title) et possède une introduction (introduction) ainsi qu’une conclusion (conclusion), possiblement vides.
Les éléments regroupés, appelés « enfants » (children) peuvent être de deux types : conteneur ou extrait. La structure d’un conteneur obéit à certaines règles :
- Un conteneur ne peut comporter un conteneur composé lui-même d’un conteneur ;
- Un conteneur ne peut comporter d’enfants directs à la fois des conteneurs et des extraits.
Au niveau de la terminologie, on désigne par « partie » tout conteneur de niveau 1, c’est-à-dire n’étant pas inclus dans un autre conteneur, et par « chapitre » tout conteneur enfant d’une partie.
Un contenu¶
Un contenu est un agencement particulier de conteneurs et d’extraits. Il est décrit par des métadonnées (metadata), détaillées ici. Une de ces métadonnées est le type : article ou tutoriel. Leur visée pédagogique diffère, mais aussi leur structure : un article ne peut comporter de conteneurs, seulement des extraits, ce qui n’est pas le cas d’un tutoriel.
Les exemples suivants devraient éclairer ces notions.
Communément appelé « mini-tutoriel » :
+ Tutoriel
+ Section
+ Section
+ Section
Communément appelé « moyen-tutoriel » :
+ Tutoriel
+ Partie
+ Section
+ Partie
+ Section
+ Section
Communément appelé « big-tutoriel » :
+ Tutoriel
+ Partie
+ Chapitre
+ Section
+ Section
+ Chapitre
+ Section
+ Partie
+ Chapitre
+ Section
+ Section
On peut aussi faire un mélange des conteneurs :
+ Tutoriel
+ Partie
+ Section
+ Section
+ Partie
+ Chapitre
+ Section
+ Chapitre
+ Section
Mais pas de conteneurs et d’extraits adjacents :
/!\ Invalide !
+ Tutoriel
+ Partie
+ Section
+ Section /!\ Impossible !
+ Partie
+ Chapitre
+ Section
+ Section /!\ Impossible !
Pour finir, un article. Même structure qu’un mini-tutoriel, mais vocation pédagogique différente :
+ Article
+ Section
+ Section
D’autre part, tout contenu se voit attribuer un identifiant unique sous la
forme d’un entier naturel (en anglais : pk, pour primary key). Cet
identifiant apparaît dans les URL, qui sont de la forme
/contenus/{pk}/{slug}. Il rend plus efficace la recherche en base de
données. Le slug, quant à lui, a le mérite d’être compréhensible par un être
humain et permet de gérer les cas de redirection 301 (voir plus bas).
Des objets en général¶
Tous les textes (introductions, conclusions et extraits) sont formatés en Markdown (dans la version étendue de ZdS).
Conteneurs et extraits sont des objets (object). Dès lors, ils possèdent
tous deux un slug (littéralement, « limace ») : il s’agit d’une chaîne de
caractères générée à partir du titre de l’objet et qui, tout en restant lisible
par un être humain, le simplifie considérablement. Un slug est uniquement
composé de caractères alphanumériques minuscules et non-accentués
([a-z0-9]*) ainsi que des caractères - (tiret) et _ (underscore).
Ce slug a deux utilités : il est employé dans l’URL permettant de consulter
l’objet depuis le site Web et dans le nom des fichiers ou dossiers employés pour le
stocker (détails plus bas). Dès lors, cette spécification impose que ce
slug soit unique au sein du conteneur parent, et que le slug du contenu
soit unique au sein de tous les contenus de ZdS.
La taille des slugs ne peut dépasser une certaine limite, définie dans le code par
ZDS_APP['content']['maximum_slug_size'] (par défaut 150). Cette limite est due à
une contrainte sur la taille maximum d’un nom de fichier sur les différents systèmes
(généralement 255 octets sur la plupart des systèmes de fichier modernes, voir à ce sujet
l’article Wikipedia correspondant (en)).
Note
À noter que l’underscore est conservé par compatibilité avec l’ancien système, les nouveaux slugs générés par le système d’édition de ZdS n’en contiendront pas.
Note
Lors du déplacement d’un conteneur ou d’un extrait, les slugs sont modifiés de manière à ce qu’il n’y ait pas de collision.
Attention
L’introduction et la conclusion d’un conteneur possèdent également un slug, pour des raisons de stockage (voir plus bas). Il ne faut pas oublier la contrainte d’unicité à l’intérieur d’un conteneur.
Attention
Suite à un changement majeur dans la librairie python-slugify, une différence peut apparaitre dans le slug
généré à partir de titres contenant des espaces. Dès lors, pour des raisons de rétro-compatibilité, c’est la version
1.1.4 de cette librairie qui est utilisée par ZdS. Par ailleurs, la commande python manage.py adjust_slugs a été
créée pour réparer les éventuels dommages, en détectant les titres posant potentielement des problèmes et en tentant
de les faire correspondre à nouveau à leur contrepartie dans le système de fichier.
Cycle de vie des contenus¶
Quelque soit le type de contenu, le cycle de vie de celui-ci reste toujours le même. Un contenu peut être rédigé par un ou plusieurs auteurs. Chaque modification est conservée afin de pouvoir retrouver l’historique des modifications et éventuellement récupérer un morceau de texte perdu. Lorsqu’un contenu est créé il rentre dans sa première étape.
Le brouillon¶
Le brouillon est la première étape du cycle de vie d’un contenu. Il donne toujours l’état le plus récent d’un contenu vu par les auteurs. Chaque fois que le contenu est modifié, c’est la version brouillon qui est mise à jour. La version brouillon est accessible uniquement pour les auteurs et validateurs d’un tutoriel. Si on souhaite donner un accès en lecture seule à nos écrits, il faut passer par la méthode adéquate.
La bêta¶
Lorsque les auteurs estiment que leur contenu a atteint un certain niveau de maturité, et qu’ils souhaitent recueillir des retours de la communauté, ils ont la possibilité de le mettre à la disposition de cette dernière le contenu en lecture seule. C’est le mode bêta.
Lors de la mise en bêta d’un contenu, un sujet est automatiquement ouvert dans
le sous-forum des contenus en cours de rédaction, contenant l’adresse de la bêta.
Cette dernière est de la forme :
/contenus/beta/{pk}/{slug}/.
Il faut en outre noter que seule une version précise du contenu est mise en bêta. Au moment de la mise en bêta, les versions brouillon et bêta coïncident mais l’auteur peut tout à fait poursuivre son travail sans affecter la seconde. Seulement, la version brouillon ne sera plus identique à la version en bêta et il ne faudra pas oublier de mettre à jour cette dernière pour que la communauté puisse juger des dernières modifications.
La validation¶
Une fois que l’auteur a eu assez de retours sur son contenu, et qu’il estime qu’il est prêt à être publié, il décide d’envoyer son contenu en validation. Via l’interface idoine, un validateur peut alors réserver le contenu et commencer à vérifier qu’il satisfait la politique éditoriale du site. Dans le cas contraire, le contenu est rejeté et un message est envoyé aux auteurs pour expliquer les raisons du refus.
L’envoi en validation n’est pas définitif, dans le sens où vous pouvez à tout moment mettre à jour la version en cours de validation. Évitez d’en abuser tout de même, car, si un validateur commence à lire votre contenu, il devra recommencer son travail si vous faites une mise à jour dessus. Cela pourrait non seulement ralentir le processus de validation de votre contenu, mais aussi ceux autres contenus !
Comme pour la bêta, la version brouillon du contenu peut continuer à être améliorée pendant que la version de validation reste figée. Auteurs et validateurs peuvent donc continuer à travailler chacun de leur côté.
La publication¶
Le cas général
Une fois que le contenu est passé en validation et a satisfait les critères éditoriaux, il est publié. Un message privé est alors envoyé aux auteurs afin de les informer de la publication, et de leur transmettre le message laissé par le validateur en charge du contenu. Il faut bien préciser que le processus de validation peut être assez long. De plus, un historique de validation est disponible pour les validateurs.
La publication d’un contenu entraîne l’exportation du contenu en plusieurs formats :
- Markdown : disponible uniquement pour les membres du staff et les auteurs du contenu
- HTML
- EPUB : format de lecture adapté aux liseuses
- Archive : un export de l’archive contenant la version publiée du contenu
Pour différentes raisons, il se peut que l’export dans divers formats échoue. Dans ce cas, le lien de téléchargement n’est pas présenté. Un fichier de log sur le serveur enregistre les problèmes liés à l’export d’un format.
Aujourd’hui, il existe des bugs dans la conversion en PDF (notamment les blocs spécifiques à ZdS), qui devraient être réglés plus tard avec la ZEP-05)
Enfin, signalons qu’il est possible à tout moment pour un membre de l’équipe de dépublier un contenu. Le cas échéant, un message sera envoyé aux auteurs, indiquant les raisons de la dépublication.
Les politiques de génération
La manière dont l’application réagira à une publication dans le but de générer – ou non – des documents téléchargeables
est configurable selon trois niveaux à affecter au paramètre ZDS_APP['content']['extra_content_generation_policy']:
- NOTHING : ne génère aucun document téléchargeable autre que le fichier markdown et l’archive zip des sources
- SYNC : génère tous les documents téléchargeables que le système peut générer de manière synchrone à la publication. C’est à dire que la génération est élevée au rang de tâche bloquante
- WATCHDOG : seul un “marqueur de publication” est généré lors de la publication, c’est un observateur externe qui viendra publier le nouveau contenu. Le site fourni un observateur externe :
python mangage.py publication_watchdog.
Attention
Le mode WATCHDOG est soumis à l’utilisation d’un autre paramètre : ZDS_APP['content']['extra_content_watchdog_dir'] qui, par défaut, créera un dossier watchdog-build à la racine de l’application
Ajouter un nouveau format d’export
Les fichiers téléchargeables générés le sont à partir d’un registre de créateur. Par défaut le registre contient les 3 formats pandoc HTML, PDF et EPUB.
Vous pouvez définir votre propre formateur qui devra alors hériter de la classe zds.tutorialv2.publication_utils.Publicator et implémenter la méthode publish.
Si vous désirez vous passer de pandoc, il vous suffira d’appeler map(PublicatorRegistry.unregister, ["pdf", "epub", "html"]).
Vous pouvez aussi simplement surcharger chacun des Publicator par défaut en en enregistrant un nouveau sous le même nom.
L’entraide¶
Afin d’aider les auteurs de contenus à rédiger ces derniers, des options lors de la création/édition de ce dernier sont disponibles. L’auteur peut ainsi faire aisément une demande d’aide pour les raisons suivantes (liste non exhaustive) :
- Besoin d’aide à l’écriture
- Besoin d’aide à la correction/relecture
- Besoin d’aide pour illustrer
- Désir d’abandonner le contenu et recherche d’un repreneur
L’ensemble des contenus à la recherche d’aide est visible via la page
/contenus/aides/. Cette page génère un tableau récapitulatif de toutes les
demandes d’aides pour les différents contenus et des filtres peuvent être
appliqués.
Il est également possible pour tout membre qui n’est pas auteur du contenu consulté de signaler une erreur, en employant le bouton prévu à cet effet et situé en bas d’une page du contenu.
Bouton permentant de signaler une erreur
Ce bouton est disponible sur la version publiée ou en bêta d’un contenu. Cliquer sur celui-ci ouvre une boite de dialogue :
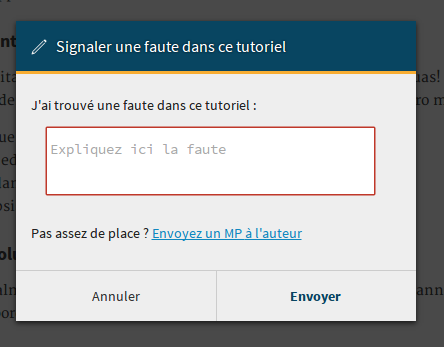
Boite de dialogue permettant de signaler à l’auteur une erreur qu’il aurait commise
Le message ne peut pas être vide, mais n’hésitez pas à être précis et à fournir des détails. Cliquer sur “Envoyer” enverra un message privé aux auteurs du contenu, reprenant votre message sous forme d’une citation. Vous participerez également à la conversation, afin que les auteurs puissent vous demander plus de détails si nécessaire.
Import de contenus¶
Zeste de Savoir permet d’importer des contenus provenant de sources extérieures.
Ce système est utilisable pour créer de nouveaux contenus à partir de zéros, ou bien si vous avez téléchargé l’archive correspondante à votre contenu, modifiée et que vous souhaitez importer les modifications.
Il suffit de faire une archive ZIP du répertoire dans lequel se trouvent les fichiers de votre contenu, puis de vous rendre soit sur “Importer un nouveau contenu”, soit sur “Importer une nouvelle version” dans n’importe quel contenu et de renseigner les champs relatifs à l’import d’une archive, puis de cliquer sur “Importer”.
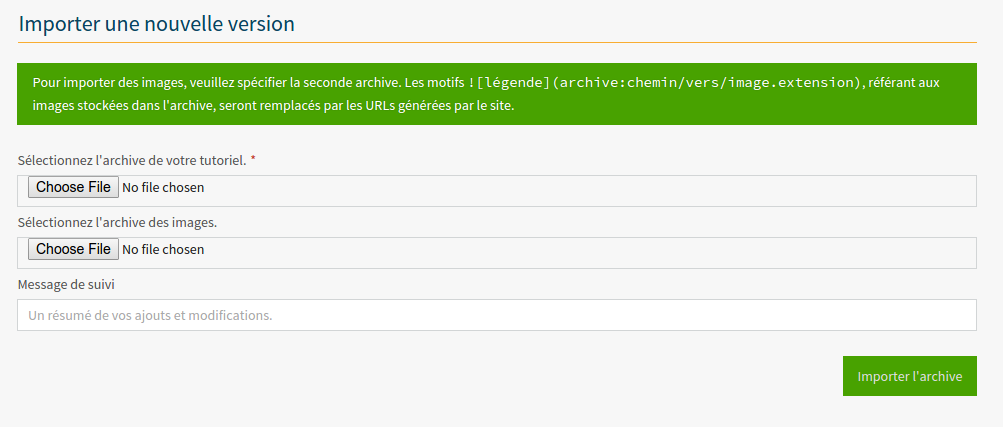
Exemple de formulaire d’importation : mise à jour d’un contenu
Import d’image¶
À noter que si vous souhaitez importer des images de manière à ce qu’elles soient
directement intégrée à votre contenu, vous devez écrire les liens vers cette image sous la
forme , puis créer une archive contenant toutes celles-ci.
Le système se chargera alors d’importer les images dans la galerie correspondante, puis de remplacer
les liens quand c’est nécessaire. Ainsi,
Voici ma belle image : 
Sera remplacé en
Voici ma belle image : 
À condition que image.png soit présent dans l’archive (à sa racine) et soit une image valide.
Règles¶
Au maximum, le système d’importation tentera d’être compréhensif envers une arborescence qui différente de celle énoncée ci-dessus. Par contre l’importation réorganisera les fichiers importés de la manière décrite ci-dessus, afin de parer aux mauvaises surprises.
Tout contenu qui ne correspond pas aux règles précisées ci-dessus ne sera pas
ré-importable. Ne sera pas ré-importable non plus tout contenu dont les
fichiers indiqués dans le manifest.json n’existent pas ou sont incorrects.
Seront supprimés les fichiers qui seraient inutiles (images, qui actuellement
doivent être importées séparément dans une galerie, autres fichiers
supplémentaires) pour des raisons élémentaires de sécurité.
Aspects techniques et fonctionnels¶
Les métadonnées¶
On distingue actuellement deux types de métadonnées (metadata) : celles
versionnées (et donc reprises dans le manifest.json) et celles qui ne le
sont pas. La liste exhaustive de ces dernières (à l’heure actuelle) est la
suivante :
- Les hash des différentes versions du tutoriel (
sha_draft,sha_beta,sha_publicetsha_validation) ; - Les auteurs du contenu ;
- Les catégories auxquelles appartient le contenu ;
- Les tags associés au contenu ;
- La miniature ;
- L’origine du contenu, s’il n’a pas été créé sur ZdS mais importé avec une licence compatible ;
- L’utilisation ou pas de JSFiddle dans le contenu ;
- Différentes informations temporelles : date de création (
creation_date), de publication (pubdate) et de dernière modification (update_date) - La galerie ;
- Le sujet de la bêta, s’il existe.
Le stockage en base de données¶
Les métadonnées non versionnées sont stockées dans la base de données, à l’aide
du modèle PublishableContent. Pour des raisons de facilité, certaines des
métadonnées versionnées sont également intégrées dans la base :
- Le titre
- Le type de contenu
- La licence
- La description
En ce qui concerne cette dernière, celle stockée en base est toujours celle de la version brouillon. Il ne faut donc en aucun cas les employer pour résoudre une URL ou à travers une template correspondant à la version publiée.
Les métadonnées versionnées sont stockées dans le fichier manifest.json. Ce
dernier est rattaché à une version du contenu par le truchement de git.
À la publication du contenu, un objet PublishedContent est créé, reprenant
les informations importantes de cette version. C’est alors cet objet qui est
utilisé pour résoudre les URLs. C’est également lui qui se cache derrière le
mécanisme de redirection si, entre deux versions, le slug du contenu change.
Le stockage via des dossiers¶
Comme énoncé plus haut, chaque contenu possède un dossier qui lui est propre
(dont le nom est le slug du contenu), stocké dans l’endroit défini par la
variable ZDS_APP['content']['repo_path']. Dans ce dossier se trouve le
fichier manifest.json.
Pour chaque conteneur, un dossier est créé, contenant les éventuels fichiers correspondant aux introduction, conclusion et différents extraits, ainsi que des dossiers pour les éventuels conteneurs enfants. Il s’agit de la forme d’un contenu tel que généré par ZdS en utilisant l’éditeur en ligne.
Il est demandé de se conformer au maximum à cette structure pour éviter les mauvaises surprises en cas d’édition externe (voir ci-dessous).
Les permissions¶
Afin de gérer ce module, trois permissions peuvent être utilisées :
tutorialv2.change_publishablecontent: pour le droit d’accéder et de modifier les contenus même sans en être l’auteur ;tutorialv2.change_validation: pour le droit à accéder à l’interface de validation, réserver, valider ou refuser des contenus ;tutorialv2.change_contentreaction: pour le droit à modérer les commentaires sur les contenus une fois publiés (masquer, éditer, ...).
Ces permissions doivent être accordées aux administateurs/modérateurs/validateurs selon les besoins via l’interface d’administration de Django.
Processus de publication¶
Apès avoir passé les étapes de validation, le contenu est près à être publié.
Cette action est effectuée par un membre du Staff. Le but de la publication
est double : permettre aux visiteurs de consulter le contenu, mais aussi
d’effectuer certains traitements (détaillés ci-après) afin que celui-ci soit
sous une forme qui soit plus rapidement affichable par ZdS. C’est pourquoi ces
contenus ne sont pas stockés au même endroit (voir
ZDS_APP['content']['repo_public_path']) que les brouillons.
La publication se passe comme suit :
- Un dossier temporaire est créé, afin de ne pas affecter la version publique précédente, si elle existe. Ce dossier est nommé
{slug}__build; - Le code markdown est converti en HTML afin de gagner du temps à l’affichage. Pour chaque conteneur, deux cas se présentent :
- Si celui-ci contient des extraits, ils sont tous rassemblés dans un seul fichier HTML, avec l’introduction et la conclusion ;
- Dans le cas contraire, l’introduction et la conclusion sont placées dans des fichiers séparés, et les champs correspondants dans le manifest sont mis à jour.
- Le manifest correspondant à la version de validation est copié. Il sera nécessaire afin de valider les URLs et générer le sommaire. Néanmoins, les informations inutiles sont enlevées (champ
textdes extraits, champsintroductionetconclusiondes conteneurs comportant des extraits), une fois encore pour gagner du temps ; - L’exportation vers les autres formats est ensuite effectué (PDF, EPUB, ...) en utilisant pandoc (en). Cette étape peut être longue si le contenu possède une taille importante. Il est également important de mentionner que pendant cette étape, l’ensemble des images qu’utilise le contenu est récupéré et que si ce n’est pas possible, une image par défaut est employée à la place, afin d’éviter les erreurs ;
- Finalement, si toutes les étapes précédentes se sont bien déroulées, le dossier temporaire est déplacé à la place de celui de l’ancienne version publiée. Un objet
PublishedContentest alors créé (ou mis à jour si le contenu avait déjà été publié par le passé), contenant les informations nécessaire à l’affichage dans la liste des contenus publiés. Lesha_publicest mis à jour dans la base de données et l’objetValidationest également changé.
Consultation d’un contenu publié¶
On n’utilise pas git pour afficher la version publiée d’un contenu. Dès lors, deux cas se présentent :
- L’utilisateur consulte un conteneur dont les enfants sont eux-mêmes des conteneurs (c’est-à-dire le conteneur principal ou une partie d’un big-tutoriel) : le
manifest.jsonest employé pour générer le sommaire, comme c’est le cas actuellement. L’introduction et la conclusion sont également affichées. - L’utilisateur consulte un conteneur dont les enfants sont des extraits : le fichier HTML généré durant la publication est employé tel quel par le gabarit correspondant, additionné de l’éventuelle possibilité de faire suivant/précédent (qui nécessite la lecture du
manifest.json).
Qu’en est-il des images ?¶
Le versionnage des images d’un contenu (celles qui font partie de la galerie rattachée) continue à faire débat, et il a été décidé pour le moment de ne pas les versionner, pour des raisons simples :
- Versionner les images peut rendre très rapidement une archive lourde : si l’auteur change beaucoup d’images, il va se retrouver avec des images plus jamais utilisées qui traînent dans son archive ;
- Avoir besoin d’interroger le dépôt à chaque fois pour lire les images peut rapidement devenir lourd pour la lecture.
Le parti a été pris de ne pas versionner les images qui sont stockées sur le serveur. Ce n’est pas critique et on peut très bien travailler ainsi. Par contre, il vaudra mieux y réfléchir pour une version 3 afin de proposer une rédaction totale en mode hors-ligne.
Passage des tutos v1 aux tutos v2¶
Le parseur v2 ne permettant qu’un support minimal des tutoriels à l’ancien format, il est nécessaire de mettre en place des procédures de migration.
Migrer une archive v1 vers une archive v2¶
Le premier cas qu’il est possible de rencontrer est la présence d’une archive hors ligne d’un tutoriel à la version 1.
La migration de cette archive consistera alors à ne migrer que le manifest. En effet, la nouvelle architecture étant bien plus souple du point de vue des nomenclatures, il ne sera pas nécessaire de l’adapter.
Un outil intégré au code de ZdS a été mis en place. Il vous faudra alors :
- Décompresser l’archive ;
- Exécuter
python manage.py upgrade_manifest_to_v2 /chemin/vers/archive/decompressee/manifest.json; - Recompresser l’archive.
Si vous souhaitez implémenter votre propre convertisseur, voici l’algorithme utilisé en Python :
with open(_file, "r") as json_file:
data = json_reader.load(json_file)
_type = "TUTORIAL"
if "type" not in data:
_type = "ARTICLE"
versioned = VersionedContent("", _type, data["title"], slugify(data["title"]))
versioned.description = data["description"]
versioned.introduction = data["introduction"]
versioned.conclusion = data["conclusion"]
versioned.licence = Licence.objects.filter(code=data["licence"]).first()
versioned.version = "2.0"
versioned.slug = slugify(data["title"])
if "parts" in data:
# if it is a big tutorial
for part in data["parts"]:
current_part = Container(part["title"],
str(part["pk"]) + "_" + slugify(part["title"]))
current_part.introduction = part["introduction"]
current_part.conclusion = part["conclusion"]
versioned.add_container(current_part)
for chapter in part["chapters"]:
current_chapter = Container(chapter["title"],
str(chapter["pk"]) + "_" + slugify(chapter["title"]))
current_chapter.introduction = chapter["introduction"]
current_chapter.conclusion = chapter["conclusion"]
current_part.add_container(current_chapter)
for extract in chapter["extracts"]:
current_extract = Extract(extract["title"],
str(extract["pk"]) + "_" + slugify(extract["title"]))
current_chapter.add_extract(current_extract)
current_extract.text = current_extract.get_path(True)
elif "chapter" in data:
# if it is a mini tutorial
for extract in data["chapter"]["extracts"]:
current_extract = Extract(extract["title"],
str(extract["pk"]) + "_" + slugify(extract["title"]))
current_extract.text = current_extract.get_path(True)
versioned.add_extract(current_extract)
elif versioned.type == "ARTICLE":
extract = Extract(data["title"], "text")
versioned.add_extract(extract)
Migrer la base de données¶
Si vous faites tourner une instance du code de Zeste de Savoir sous la version 1.x et que vous passez à la v2.x, vous allez
devoir migrer les différents tutoriels. Pour cela, il faudra simplement exécuter la commande python manage.py migrate_to_zep12.py.
Récapitulatif des paramètres du module¶
Ces paramètres sont à surcharger dans le dictionnaire ZDS_APP[‘content’]
repo_private_path: chemin vers le dossier qui contiend les contenus durant leur rédaction, par défaut le dossier sera contents-private à la racine de l’applicationrepo_public_path: chemin vers le dossier qui contient les fichiers permettant l’affichage des contenus publiés ainsi que les fichiers téléchargeables, par défaut contents-publicextra_contents_dirname: nom du sous-dosssier qui contient les fichiers téléchargeables (pdf, epub...), par défaut extra_contentsextra_content_generation_policy: Contient la politique de génération des fichiers téléchargeable, ‘SYNC’, ‘WATCHDOG’ ou ‘NOTHING’extra_content_watchdog_dir: dossier qui permet à l’observateur (siextra_content_generation_policyvaut"WATCHDOG") de savoir qu’un contenu a été publiémax_tree_depth: Profondeur maximale de la hiérarchie des tutoriels : par défaut3pour partie/chapitre/extraitdefault_licence_pk: Clé primaire de la licence par défaut (« Tous droits réservés » en français), 7 si vous utilisez les fixturescontent_per_page: Nombre de contenus dans les listing (articles, tutoriels, billets)notes_per_page: Nombre de réactions nouvelles par page (donc sans compter la répétition de la dernière note de la page précédente)helps_per_page: Nombre de contenus ayant besoin d’aide dans la page ZEP-03feed_length: Nombre de contenus affiché dans un flux RSS ou ATOM,user_page_number: Nombre de contenus de chaque type qu’on affiche sur le profil d’un utilisateur, 5 par défaut,default_image: chemin vers l’image utilisée par défaut dans les icônes de contenu,import_image_prefix: préfixe mnémonique permettant d’indiquer que l’image se trouve dans l’archive jointe lors de l’import de contenubuild_pdf_when_published: indique que la publication générera un PDF (quelque soit la politique, siFalse, les PDF ne seront pas générés, sauf à appeler la commande adéquate),maximum_slug_size: taille maximale du slug d’un contenu